Developing Development
08 Feb 2022There’s no way I wrote this…‘write’?
I recently had a friend ask me about a project I wrote two semesters ago. That goal of the project was to create simplified router. If you’re familiar with the OSI model, students were tasked with creating code to simulate the transport and network layers. My friend needed advice to understand how to start the project, so I decided to look at my code and see what I did(I didn’t show them the code, but I wanted to offer general advice). Although the code was commented thoroughly, I realized I could barely make heads or tails of the code. I had forgotten how this code even worked, and unfortunately couldn’t help them as well as I could have. It had occurred to me if there was something in this code that needed to change, it would be a difficult task. Fast-forward to just over a week later where there was an ACM tech talk which featured two Google senior software engineers. Their presentation revolved around observations they had noticed while working on various projects. This was significant considering the codebase for these projects were to be used for long periods of time and be seen by multitudes of staff of various skill levels.
function GoodCodebase(time, scale, tradeoffs)
It’s only a matter of time.
There were three broad concepts to consider resilient codebase. Whenever you’re developing code, one should consider how long it would be used or Time. They should also take into account who will be developing/improving/changing the codebase: Scale. Finally, they should try to weigh the Tradeoffs that will need to be made in order to get optimal results. When looking at the concept of Time, an interesting idea that came up was the concept of sustainability. Before any code is written it’s important to understand it’s life expectancy and from there steps must be taken to make sure that a program is ‘resilient’ to change. This means that the codebase is written in such a way, upgrading and maintaining the code can be done while keeping the originally written code.
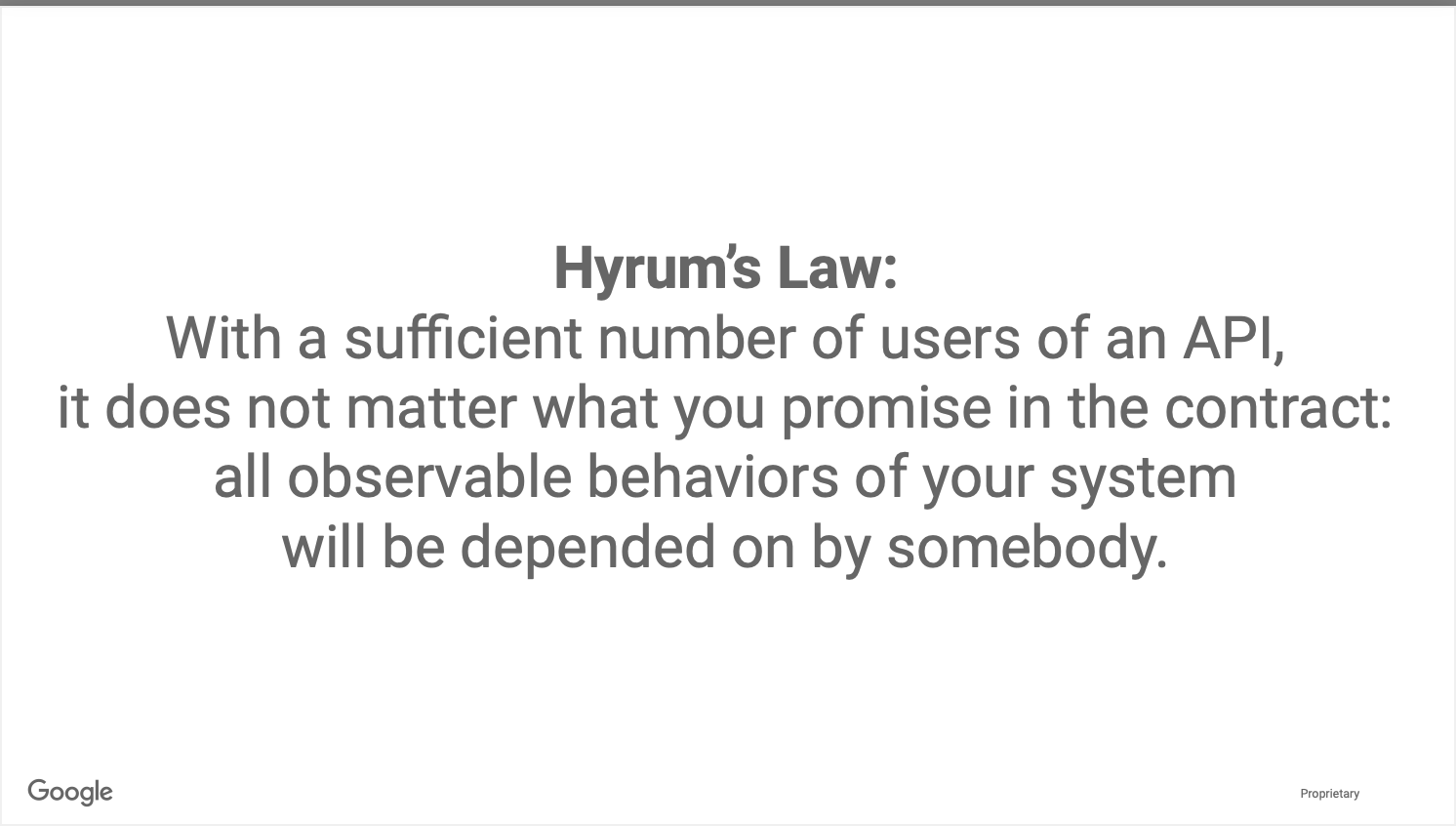
The picture above describes an observation found by one of the engineers. This reminds me of Murphy’s law which is summed up to “If something can go wrong it will”. This is the same with a codebase. If you leave a codebase around long enough something bad will happen to it. Whether it’s software dependencies, security issues, or getting a new set of developers, the codebase needs to be resilient to changes that occur during its lifetime.
Scale tips!
The concept of scale stems from the problem of having teams of various sizes developing code for various time frames. How should the development process change when the codebase has new developers every year? What kind of problems can arise from having repository branches that have been worked on for long periods of time? These are questions one must consider when navigating through the software development process. To introduce the concept of scale they talked about deprecation and the various approaches that are used to handle issue of codebase deprecation. One of the methods is to have a single person create a mandate to handle deprecated software or methods. This mandate would need to be enforced by the team members in charge of various sections of the code. Another method is having a single person go into the API and make changes through refactoring. In my opinion that last method seems a little barbaric, as having a single developer have the responsibility for an entire API can be quite a daunting task. Google has adopted the practice of having a single specific team be in charge of that codebase. So much so, that they become specialists and end up being able to make changes quicker due to their familiarity with the code base.
There also was the topic of the ‘merge meeting’, which is when developers meet up just before a merge of various branches occurs. There is research showing that branches that with lots of changes in various portions of the codebase can lead to frequent merge conflicts. Therefore, Google has adopted “Trunk-based development”. By merging branches with a low volume of changes to the codebase, you get less merge conflicts. More importantly, this allowed for there to be little to no merge meetings. Which meant merges could be done at a quicker pace while reducing the ‘communication overhead’ for setting up and carrying out these meetings.
Trade on, tradeoff.
Going from writing code to releasing a product should have as many steps as necessary. In the presentation, the presenter mentions that it’s important to have intermediate steps to prevent releasing a product with lots of bugs. The presenter acknowledges that no product is perfect, and that bugs will always be an issue. The key is being able to catch them at earlier stages of development in order to make changes that aren’t so drastic or urgent. This means that there’s a possibility where the code takes longer to release, but you have a much lower chance of your users experiencing bugs. This the same for costs, it takes a lot more time and money to fix bugs found in later steps of code development.
When it comes to designing processes within the code development processes, it’s never too late to change something. This is especially true as software vulnerabilities can make or break your program after release. Making evidence based decisions can assist leadership in the designing or re-evaluating of certain development and testing processes. Working with the results from testing or user feedback allows for easy decisions making when it comes to evaluating what to do whenever an issue occurs. That way leadership isn’t throwing ideas against a wall and hoping that something sticks.
Isn’t it obvious?
When I first heard about this presentation, I thought it was going to be be an in-depth into the “secrets” of what makes Google software engineering (SWE) so great. When in reality, it was all advice that seemed obvious. They started the presentation by saying “There is no silver bullet”, and presented their observations they’ve had over the years. But I think it also shows how new I am to SWE. All the concepts they were highlighting just makes sense. I’ve never made any production based code, and all of their talking points about scale, sustainability, and their tradeoffs sounded like they were standard SWE practices. But I’m sure that other developers who have had similar experiences would appreciate their insight. I think it validated some negative experiences that other developers have had and allowed for their grievances to be heard.
I think if I had written my router project code with the thought of seeing it again in a year I would have been able to give my friend better advice. But that instance also highlight some of their talking points. If I was an “expert” who looked at the codebase consistently I would have had a better idea of how my router program worked. The previous developer (me a year ago) pretty much slapped it together and said “welp it works, so I’m done”. There was no code review resulting in the next developer (me a couple of weeks ago) looking at it and unable to make heads or tails of it. Not only that but if I had to scale this to other developers they also would have had issues reading that messy code. If I had taken the time to develop my development process then I could have had a much cleaner product. This experience of sharing my code combined with the insight from the engineers showed me what I need to be conscious of whenever I’m developing a project.